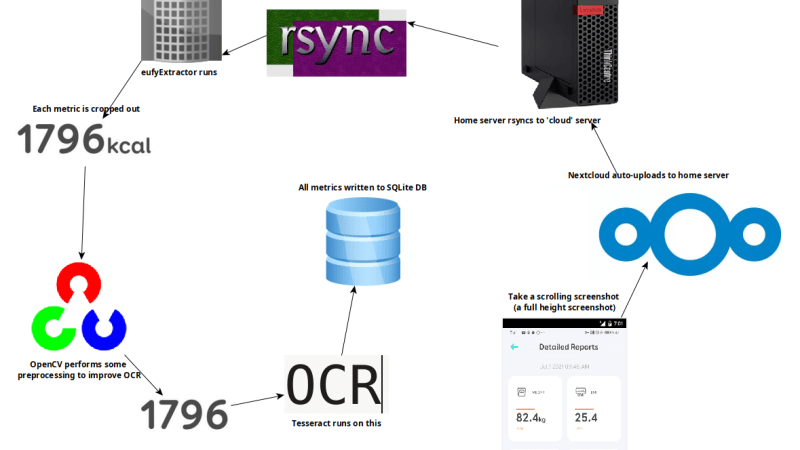
[Kevin Norman] bought himself a smart scale to record data for his analysis, but he found that it was not easy to extract data from the device. It turns out that the only way to get data from his scale is to view the data in a mobile application. Screen capture is a long-standing method to extract data from uncooperative systems. Therefore, [Kevin] promises to regularly obtain full height screenshots from applications and use optical character recognition (OCR) to obtain numbers, but the process to achieve this goal is extremely long and full of dead ends.
First, although OCR is reliable, it requires correct conditions. What eventually became a big problem was the way applications attached units (kg,%) to numbers. They are not only hidden very close, but also about half the height of the number itself. It has been proved that the height of mixed and matched characters, in addition to making characters close to each other, is also tailored to solve the problem of OCR reliability.
The solution to this particular problem comes from an unexpected angle. [Kevin] used an open source OCR program called Tesseract and joined an IRC community “Tesseract” for comments after exhausting his choice. Confused online community members told [Kevin] that they had nothing to do with OCR #tesseract. In fact, they were a community of open-source 3D FPS shooting games with the same name. Fortunately, one of the members actually had OCR experience and proposed a winning method: preprocessing the image with OpenCV, detecting and creating a bounding box around each element with CV2. Findcontents(). If one element is higher than the decimal point but shorter than all other elements, it is discarded. After completion, some adjustments need to be made, but the finish line is finally in front of us.
Now, Kevin can use the balance in the morning to take screenshots. In less than half a minute, the results are imported into the database and visualized. The resulting workflow may seem to be recognized by Rube Goldberg, but it is effective!