Most of us turn off the sound from time to time when we watch TV. Although the story is usually understandable at least to some extent, the lack of sound track often limits our ability to fully understand what is happening.
Similarly, it’s easy to miss a lot of information just by listening to the sound from another room. Multimodality, which combines images, sounds and other details, greatly enhances our understanding of what is happening, whether on TV or in the real world.
The same seems to be true of AI. A new Q & a model called Merlot reserve realizes out of the box prediction and reveals a powerful multimodal common sense understanding. It was recently developed by the Allen Institute for artificial intelligence (AI2), the University of Washington and the University of Edinburgh.
As part of a new generation of AI applications that support semantic search, analysis and question answering (QA), the system is trained by “watching” 20 million YouTube Videos. The capabilities demonstrated have been commercialized by 12 laboratories and start-ups such as clipr.
Merlot reserve (hereinafter referred to as reserve) represents the multi-mode event representation learning over time, has the re-entry supervision of events, and is constructed based on the Merlot model before the team. It is pre trained on millions of videos and learns from their combined input of images, audio and transcription. A single frame allows the system to learn in space, while video level training provides it with time information and trains it to understand the relationship between elements that change over time.
“AI will deal with things differently than humans,” said Ron Zeller, a computer scientist and project leader. “However, if we want to build robust AI systems, there are some general principles that will be difficult to avoid. I think multimode mode must be in this range.”
Rowan Zellers is a researcher at the University of Washington and the Allen Institute for artificial intelligence.
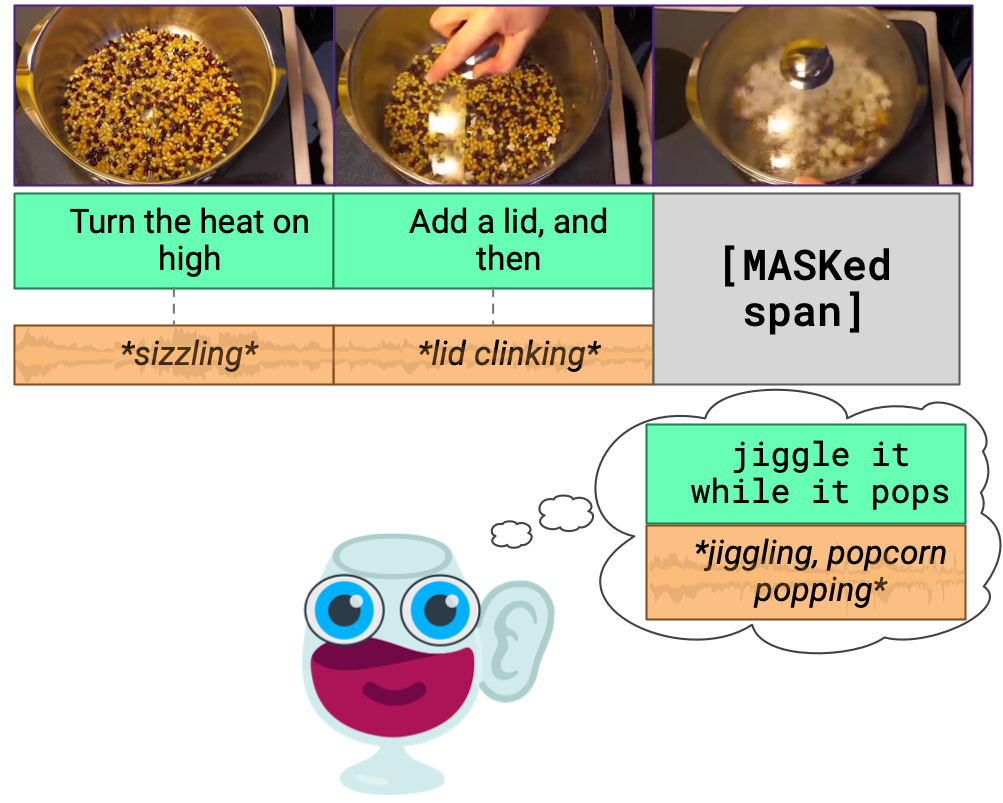
Because we live in a dynamic world, the team wants to explore how to build machines that can learn from vision, language and sound. In an example of a newspaper, someone is cooking popcorn. From images and conversations alone, we can imagine the sound accompanying them. The sound of uncooked corn grains moving on the metal surface of the pot may eventually turn into a vibrant “bang” sound, as they turn into fluffy white popcorn.
This prediction is called “learning from re-entry”, in which the time-locked correlation enables one model to educate others. Some developmental psychologists assume that this is how we learn about vision and the world without teachers. This is also the basis of the name of the reserve: re-entry supervision of activities.
The audio clip and the video clip are “masked” on the system for 40 seconds. Reserve then learns by selecting the correct hidden clip from four multiple choice options. Next, choose from four possible reasons to prove the rationality of the answer.
This method can not only enable the reserve team to obtain the most advanced results through semi supervised training, but also make a strong zero shooting prediction. In this case, an example of zero shot prediction may be a question, such as “what is this person doing?” This can be manually or automatically rewritten to statements such as “this person is [mask]”, and then the model makes multiple-choice predictions for a set of options provided, such as “cooking popcorn” or “eating popcorn”
Reserve fine tuned several large data sets for cognitive level visual understanding: VCR, tvqa and dynamics-600. Reserve shows the most advanced performance, which is 5%, 7% and 1.5% higher than previous works respectively. By adding audio, the accuracy of the model on dynamics-600 is 91.1%.
VCR (visual commonsense reasoning) is a large-scale data set without audio, which is used for visual understanding at the cognitive level. Tvqa is a large video QA data set based on six popular TV programs (friends, big bang theory, how I know your mother, house M.D., Grey’s anatomy and Castle). Finally, kinetics-600 is a collection of 650000 video clips, covering hundreds of human action classes.
According to the paper on this research, which will be presented at the IEEE / CVF International Conference on computer vision and pattern recognition in June, reserve shows significant performance improvements compared with the competitive model. For example, it requires a fifth floating point operation used by the visual Burt multimodal model.
The project team expects that the video pre training model may one day help users with low vision or hearing loss, or be used to tap insights into video viewing trends. However, they also recognize that the data set used to train reserve talents inevitably brings deviations that need to be solved.
In addition to what is said, audio can also provide a lot of additional contextual information. According to our own experience, this is not surprising to us, but it is interesting that the performance of artificial intelligence can also be significantly improved. This may be because new statistical correlations can be generated when synchronizing additional information.
“Audio is a lot of things. It’s not just sound, it’s sound effects. Hearing these sound effects will really improve your understanding of the world,” Zeller said.
“Another thing is intonation, which is the driving force of human communication. If you only look at words, not audio context, you will miss a lot. But if someone says the word with a specific emotion, the model can do better. In fact, we find that it does.”
Mello and reserve are part of the AI2 mosaic team, which is committed to developing systems that can measure and develop machine common sense. For decades, machine knowledge has been a hot field in the field of artificial intelligence. Being able to consider and predict the real-world relationships between different objects and processes will make our AI tools more useful to us.
However, just loading a series of facts and rules about how the world works into a system and expecting it to work is not enough. The world is too complex to do this. On the other hand, we learn from the moment we are born through the interaction between various senses and the environment. We gradually understand what happened in the world and why. Some machine knowledge projects use a similar approach. For Mello and reserve, adding additional patterns can provide additional information like our senses.
“I think in the medium to long term, what I’m really interested in is artificial intelligence, which can talk to us in a variety of ways, such as audio and gestures, so that it can connect with what we’re doing,” Zeller observed. The authors of the project paper “Melo reserve: neural script knowledge obtained through vision, language and sound” include Rowan Zeller, Lu Jiasen, Lu Ximing, Yu Yongjie, Zhao Yanpeng, Mohamed Salehi, aditia kusupati, Jack Hessel, Ali fahadi and Yejin CAI. A demo of reserve can be found on AI2.